# 文件系统概述
# 文件系统及其目标
信息是计算机系统中的重要资源,所有应用系统都需要存储和检索信息。操作系统的文件系统(File System)正是为了满足信息管理的需要而设计的,它负责信息的组织、存储和访问。
存储信息通常有三个基本要求:
- 大容量:能够存储大量的信息。
- 持久性:能够长期保存信息,即使系统断电也不会丢失。
- 可共享:允许多个进程或用户方便地共享信息。
为了满足这些要求,操作系统将信息以一种逻辑单元——即文件的形式,存储在磁盘等持久性存储介质上。文件系统作为操作系统中专门管理文件的部分,其核心目标是管理文件的存储、检索、更新,提供安全可靠的共享和保护手段,并为用户提供方便易用的接口。
# 文件系统的核心功能
- 方便的文件访问与控制:用户通过符号名称(即文件名)来标识和访问文件,无需关心其物理存储细节。
- 并发文件访问与控制:在多道程序环境中,支持多个进程对文件进行并发访问,并提供必要的同步与互斥机制。
- 统一的用户接口:为不同类型的存储设备提供统一、抽象的访问接口,简化用户操作和应用程序开发。
- 灵活的访问权限管理:在多用户系统中,允许为不同用户设置对同一文件的不同访问权限(如读、写、执行)。
- 优化性能:提升文件系统的存储效率、检索速度以及读写性能。
- 差错恢复:具备验证文件数据正确性的能力,并能在发生错误时进行一定程度的恢复。
# 文件系统的性能与用户体验
对大多数用户而言,文件系统是操作系统中最为可见的部分。操作系统本身、所有用户程序及数据都由文件系统负责存储和管理。因此,文件系统在操作系统接口中占据了核心地位,用户对操作系统的使用体验在很大程度上取决于文件系统的表现。
# 文件系统的两种视图
- 用户视图:关注文件系统如何呈现给用户。这包括文件的组成、命名规则、保护机制以及可对文件执行的操作等。这是从抽象和使用的角度来看待文件系统。
- 实现视图(操作系统视图):关注文件系统底层的实现机制。这包括文件和目录的具体实现方式、存储空间的管理策略、文件在磁盘上的物理位置、与设备驱动的接口以及性能优化等。这是从设计和实现的角度来看待文件系统。
# 文件系统的硬件支持
# 磁盘分区与引导
# MBR 分区方案
物理磁盘以扇区(Sector) 为单位进行寻址,扇区大小由硬件决定,通常为 512 字节。分区(Partition) 是磁盘上一组连续扇区的集合。
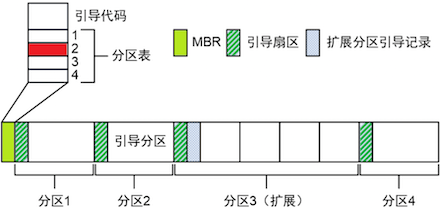
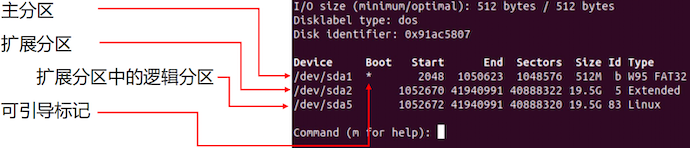
- 主引导记录(MBR):位于磁盘的 0 号扇区,用于引导计算机。MBR 包含引导代码和分区表。
- 分区表:记录了每个分区的起始和结束地址,以及该分区是否可引导的标记。
- 分区限制:一个硬盘最多可以包含 4 个主分区。为了支持更多分区,可以将其中一个主分区设置为扩展分区,并在其内部创建逻辑分区。
# GPT 分区方案
传统的 MBR 分区方案最大只支持 2TB 的磁盘容量。为了支持更大容量的磁盘,引入了 GPT(GUID Partition Table)分区方案。
- 容量:理论上无存储容量限制。
- 分区数量:没有主分区的数量限制。
- 兼容性:为了兼容旧系统,GPT 分区表的前部也包含一个“保护引导(Protective MBR)”。
# PC 系统引导过程
- PC 开机后,首先执行 BIOS(或 UEFI)。
- BIOS 选择一个引导设备(如硬盘),读取其 MBR 到内存中,并将控制权交给 MBR 中的引导代码。
- MBR 的引导代码扫描分区表,找到被标记为可引导的活动分区(Boot Partition)。
- 引导代码将活动分区的第一个扇区——引导扇区(Boot Sector) 读入内存,并将控制权交给引导扇区中的代码,由后者继续加载操作系统。
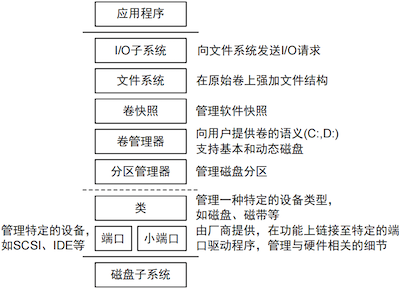
# 存储抽象:卷与动态磁盘
为了提高磁盘的读写速度和存储容量,业界发展出了 RAID(独立磁盘冗余阵列)技术。为适应这类技术,现代操作系统将磁盘存储类型分为基本存储和动态存储。
# 基本存储与动态存储
-
基本存储(Basic Storage):
- 依赖于传统的 MBR 或 GPT 分区方案。
- 包含主分区、扩展分区和逻辑驱动器。
- 调整分区大小通常需要借助第三方工具,且可能导致数据丢失。
-
动态存储(Dynamic Storage):
- 不使用传统的分区表,而是将物理磁盘组织成一个或多个卷。
- 提供了更灵活的磁盘管理功能,可以在不重启系统的情况下调整卷的大小。
- 解决了基本磁盘扩容不便的局限性,实现了存储空间的动态收缩和扩展。
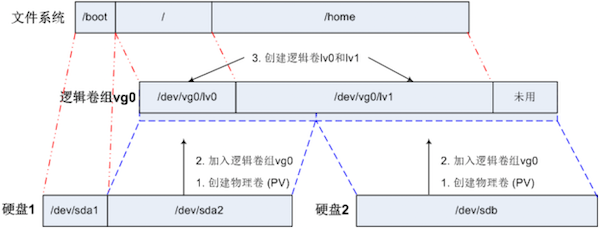
- 实现动态存储的关键组件是卷管理器,例如 Windows 中的 LDM(逻辑磁盘管理)和 Linux 中的 LVM(逻辑卷管理)。
# 卷 (Volume)
卷是由一个或多个物理磁盘上的可用空间组成的存储单元。操作系统可以像对待单个物理磁盘一样,使用某种文件系统对卷进行格式化并为其分配盘符或挂载点。
- 简单卷(Simple Volume):使用单个磁盘上的可用空间,描述了单个分区内的扇区。简单卷可以在同一个磁盘内扩展。
- 多分区卷(Multi-partition Volume):描述了多个分区中的扇区,文件系统将其作为一个逻辑单元进行管理。常见的类型包括:
- 跨区卷(Spanned Volume):将多个物理磁盘的空间连接起来,形成一个更大的卷。
- 带区卷(Striped Volume, RAID-0):将数据分块交错存储在多个磁盘上,以提高读写性能。
- 镜像卷(Mirrored Volume, RAID-1):将数据完全复制到两个或多个磁盘上,以实现数据冗余。
- RAID-5 卷:将数据和奇偶校验信息交错存储在多个磁盘上,兼顾性能和冗余。
# Windows 动态存储示例
# Linux 逻辑卷管理 (LVM)
# 文件系统格式
文件系统是在卷(或分区)上创建的。文件系统格式定义了文件数据在卷上的具体存储方式,它直接影响了文件系统的特性。
-
FAT 文件系统格式:
- 核心是文件分配表(File Allocation Table, FAT)。通常有两份 FAT 表互为备份。
- 文件卷中的每个簇都对应一个 FAT 表项,文件数据块采用链式分配方法。

-
Unix 类操作系统的文件系统格式:
- 超级块(Superblock):包含文件系统的所有关键参数,如块大小、i 节点数量等。
- 空闲块信息:用于管理未使用的磁盘块,通常使用位图或链表。
- i 节点(inode):一个数据结构数组,每个 i 节点对应一个文件或目录,存储了其元数据和数据块指针。

# 核心术语
-
簇(Cluster)
- 文件系统用于管理磁盘空间的可寻址数据块,其大小是扇区大小的整数倍。
- 较大的簇可以提高 I/O 性能,但可能因内部碎片而浪费更多的磁盘空间。
-
元数据(Metadata)
- 用于支持文件系统管理而存储在卷上的数据,例如文件和目录的位置、属性、权限等信息。
- 元数据对应用程序通常是透明且不可直接访问的。
# 文件
# 文件的定义与属性
文件是一种抽象机制,它提供了一种在磁盘上保存信息并方便以后读取的方法,使用户无需关心信息的具体存储方式和位置。
从逻辑上看,文件是一组具有标识符号的、在逻辑上具有完整意义的信息项的集合。这个标识符号就是文件名。
一个文件通常包括两部分:
- 文件体:文件本身所包含的数据信息。
- 文件属性(元数据):用于描述和管理文件的信息,如文件名、文件内部标识、存储地址、大小、类型、访问权限、创建/修改时间等。
# 文件命名与扩展名
不同的操作系统有不同的文件命名规则,通常涉及以下方面:
- 长度:文件名允许的最大字符数。
- 字符集:允许使用的字符(如数字、特殊符号等)。
- 大小写敏感性:是否区分文件名中的大小写字母。
- 文件扩展名:文件名中用于标识文件类型的后缀。
文件扩展名通常用于提示文件内容。在 Linux/UNIX 中,扩展名只是一种约定;而在 Windows 中,操作系统会为扩展名注册关联的应用程序。
# 文件的逻辑结构
文件的逻辑结构是指从用户角度看到的文件组织形式,它独立于文件在外部存储设备上的物理结构。
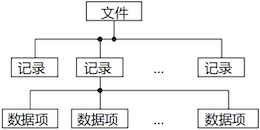
常见的逻辑结构有:
-
无结构文件(字节流文件)
- 文件体由连续的字节序列构成,不划分记录。这是最简单、最灵活的结构。
-
累积文件(Pile File)
- 文件由一系列无结构的记录组成,记录之间通过特定分隔符划分。新记录总是追加到文件末尾,如日志文件。
-
顺序文件(Sequential File)
- 文件由一系列大小相同且按某个关键字排序的记录组成。新记录通常先写入临时文件,再定期合并到主文件中。
-
索引顺序文件(Indexed-Sequential File)
- 在顺序文件的基础上建立索引,以加快检索速度。索引项指向主文件中记录的某个区间。新记录可暂存到溢出文件中。
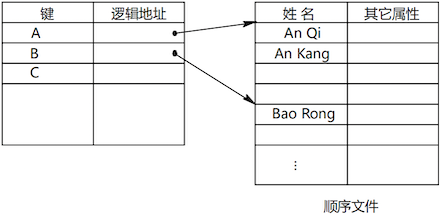
-
索引文件(Indexed File)
- 文件中的记录大小不必相同,也不必排序。系统为记录的某个(或多个)关键字建立索引,每个索引项直接指向一个记录。这种结构便于随机访问。
-
哈希文件(Hashed File)
- 记录大小相同,其在文件中的物理位置由一个哈希函数根据记录的关键字计算得出。访问速度快,但可能存在空间浪费。
# 文件类型
文件可以从不同角度进行分类:
- 按性质和用途:系统文件、用户文件、库文件。
- 按信息保存期限:临时文件、永久文件、档案文件。
- 按保护方式:只读文件、读写文件、可执行文件。
- 按逻辑结构:流式文件、记录式文件。
- 按物理结构:顺序(连续)文件、链接文件、索引文件。
在 Linux/UNIX 系统中,文件主要分为三类:
- 普通文件:包含用户信息,如文本文件、二进制程序。
- 目录文件:用于组织和管理文件系统结构的系统文件。
- 特殊文件(设备文件):将外部设备(如磁盘、终端)抽象为文件,包括字符特殊文件和块特殊文件。
# 文件存取方式
- 顺序存取:从文件头开始,按顺序依次读取字节或记录。
- 随机存取:可以不按顺序,直接访问文件中的任意字节或记录。
# 文件操作
以下以 Linux/UNIX 的系统调用为例,介绍常见的文件操作:
- 创建文件
creat- 创建一个空文件或将已有文件截断为空。
fd = creat(name, pmode);
- 打开文件
open- 打开一个已存在的文件,以便进行读写。
fd = open(name, rwmode[, pmode]);rwmode可指定只读(O_RDONLY)、只写(O_WRONLY)或读写(O_RDWR)。
- 关闭文件
close- 关闭一个已打开的文件,释放相关资源。
close(fd);
- 读写文件
read/write- 从文件读取数据或向文件写入数据。
n = read(fd, buffer, size);n = write(fd, buffer, size);
- 定位文件指针
lseek- 改变下一次读写操作在文件中的位置。
newpos = lseek(fd, offset, origin);origin可指定从文件头(SEEK_SET)、当前位置(SEEK_CUR)或文件尾(SEEK_END)开始偏移。
# 目录
# 文件控制块 (File Control Block, FCB)
**文件控制块(FCB)**是操作系统为管理文件而设置的核心数据结构,它存放了管理文件所需的所有属性信息,是文件存在的唯一标志。
FCB 的内容通常包括:
- 基本信息:文件名、文件内部标识符(如 i 节点号)。
- 物理位置信息:文件在磁盘上的存储地址。
- 结构信息:文件长度、逻辑结构、物理结构。
- 访问控制信息:文件所有者、访问权限、口令。
- 管理信息:创建/修改/访问日期、共享计数等。
# 目录的定义与实现
- 文件目录:所有文件的 FCB 组织在一起,构成了文件目录。可以说,文件目录是 FCB 的有序集合。
- 目录项:构成文件目录的每个条目。一个目录项可以就是文件的 FCB,或者包含文件名和指向 FCB 的指针。
- 目录文件:为了便于管理和持久化存储,文件目录通常以文件的形式保存在外存上,这种文件被称为目录文件。
# 目录结构
- 一级目录系统:整个文件系统中只有一个目录文件,所有文件都在这个目录中。
- 缺点:查找效率低、不允许重名、不便于文件共享。
- 两级目录系统:目录分为两级:主文件目录(MFD)和用户文件目录(UFD)。主目录记录用户名及其对应的用户目录位置,每个用户拥有自己的独立目录。
- 优点:解决了文件重名问题,提高了查找效率。
- 层次目录系统(树状目录):将目录组织成一棵树形结构。一个目录中可以包含文件,也可以包含子目录。这是现代操作系统普遍采用的结构。
- 优点:结构清晰,便于文件分类和管理。
# 路径名
在树状目录结构中,需要一种方式来唯一地标识一个文件,这就是路径名。
- 绝对路径名:从根目录开始,直到目标文件或目录所经过的完整路径。
- 相对路径名:从用户指定的当前工作目录开始,到目标文件或目录的路径。
# 目录操作
以下以 Linux/UNIX 的系统调用为例:
- 创建目录
mkdir:int mkdir(const char *path, mode_t mode); - 删除目录
rmdir:int rmdir(const char *path); - 打开目录
opendir:DIR *opendir(const char *dirname); - 关闭目录
closedir:int closedir(DIR *dirp); - 读取目录项
readdir:struct dirent *readdir(DIR *dirp); - 创建链接
link:int link(const char *existing, const char *new); - 删除目录项
unlink:int unlink(const char *path);
# 文件系统的实现
# 文件存储方式
文件存储方式指的是文件在磁盘上的物理结构,主要有以下几种:
# 连续分配
文件数据存放在一组连续的磁盘块(簇)中。目录项中只需记录文件的起始块号和总块数。
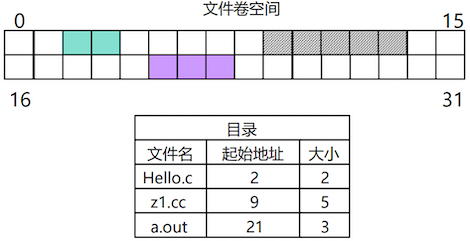
- 优点:
- 实现简单,支持顺序存取和随机存取。
- 顺序读写速度快,因为所需的磁盘寻道次数最少。
- 缺点:
- 文件不能动态增长。
- 容易产生外部碎片,浪费磁盘空间。
# 链接分配
文件的信息存放在若干不连续的磁盘块中,每个块内包含一个指向下一个数据块的指针。目录项中只需记录文件的起始块号。
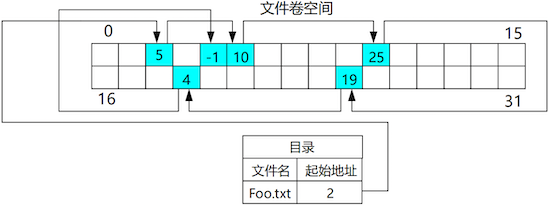
- 优点:
- 有效利用磁盘空间,没有外部碎片问题。
- 文件可以动态增长。
- 缺点:
- 随机访问性能差,必须从头遍历链表。
- 指针占用了一部分存储空间。
- 可靠性较低,指针丢失或损坏会导致文件数据丢失。
# FAT 分配
这是链接分配的一种变体。它将所有数据块的链接指针集中存放在一个独立的**文件分配表(File Allocation Table, FAT)**中,而不是分散在各个数据块里。
- 优点:
- 兼具链接分配的优点(无外部碎片、动态增长)。
- 随机访问性能优于简单的链接分配,因为可以先在内存中查找 FAT 表。
- 缺点:
- FAT 表本身占用一定的磁盘空间。
- 对于大容量磁盘,FAT 表可能非常大。
# 索引分配
系统为每个文件创建一个名为 **i 节点(inode)**的索引块,该块专门用于存放指向文件数据块的地址指针。目录项中只需包含指向该文件 i 节点的指针。
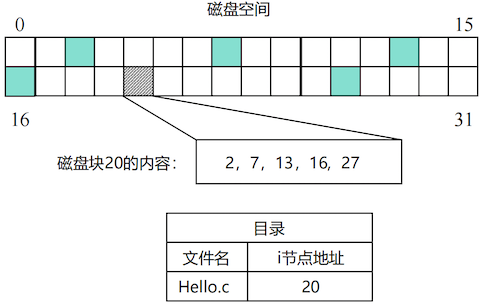
- 优点:
- 同时支持高效的顺序存取和随机存取。
- 文件可以动态增长,且没有外部碎片问题。
- 缺点:
- 索引块本身会带来额外的存储开销。
- 对于小文件,索引开销相对较大;对于大文件,可能需要多级索引,增加访问复杂度。
# 目录实现
# 目录项内容
- 简单目录:目录项中直接存放文件的所有属性(即完整的 FCB)。
- 使用 i 节点的目录:目录项中只包含文件名和指向该文件 i 节点的指针。文件的所有其他属性都存储在 i 节点中。这是 Unix/Linux 采用的方式,便于实现硬链接。
# 变长文件名存储
- 行内存储:每个目录项的长度可变,直接包含文件名。
- 缺点:删除文件后会留下可变长度的空隙,管理复杂。
- 堆中存储:目录项本身具有固定长度,文件名则被放置在目录文件末尾的一个特殊区域(堆)中,目录项通过指针引用它。
- 优点:目录项删除和复用管理简单。
# 共享文件
# 文件共享机制
在多用户协作的环境中,常常需要让多个用户共享同一个文件。文件共享意味着同一个文件可以出现在不同用户的目录中。
# 硬链接 (Hard Links)
在采用 i 节点的系统中,多个目录项可以直接指向同一个 i 节点。每个这样的目录项就是一个硬链接。
- 实现:i 节点中维护一个“链接计数”,记录有多少个目录项指向它。
- 删除:删除文件时,仅删除对应的目录项并将 i 节点的链接计数减 1。只有当链接计数变为 0 时,系统才会真正删除 i 节点并释放其占用的数据块。
- 问题:如果用户 C 删除了文件,系统需要判断是否还有其他用户(如 B)在引用它,避免误删数据或产生悬空指针。链接计数机制解决了这个问题。
# 符号链接 (Symbolic Links)
符号链接(或软链接)是创建一个特殊类型的文件(LINK),其内容是它所链接的文件的路径名。
- 实现:当系统访问符号链接时,它会读取其中的路径名,然后转而访问该路径对应的文件。
- 优点:可以跨越不同的文件系统,也可以链接到目录。
- 缺点:存在额外的访问开销(需要解析路径)。如果原始文件被删除,符号链接将失效,成为一个“悬空链接”。
# 磁盘空间管理
# 簇(Cluster)的选择
簇是文件系统分配磁盘空间的最小单位。簇大小的选择是一个权衡过程:
- 大簇:
- 优点:提高 I/O 性能(单次 I/O 读取更多数据),减小管理开销(如 FAT 表的大小)。
- 缺点:内部碎片问题严重。即使文件很小,也必须占用一整个大簇,造成空间浪费。
- 小簇:
- 优点:空间利用率高,内部碎片少。
- 缺点:管理开销大(需要更多的簇编号),可能导致 I/O 性能下降。
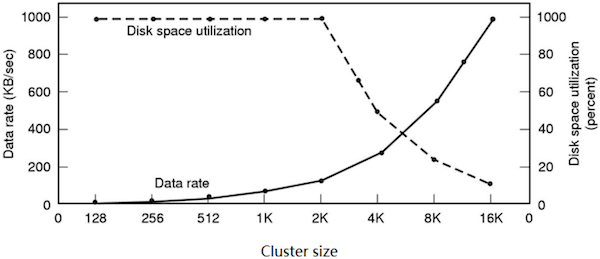
文件卷容量与簇大小的关系:
- 如果簇的总数(即簇编号位数)固定,那么文件卷容量越大,簇就必须越大,导致浪费增多。
- 如果簇的大小固定,那么文件卷容量越大,需要的簇总数就越多,可能导致簇编号空间不足(例如 FAT16 的限制)。
# 空闲空间管理
文件系统必须跟踪哪些磁盘块是空闲的,以便为新文件分配空间。主要方法有两种:
# 空闲块位图
使用一个位图(Bitmap),其中每一位对应一个磁盘块。若位为 1,表示对应块已分配;若为 0,表示空闲。
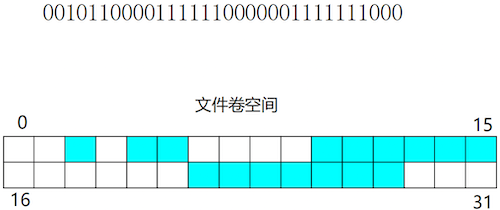
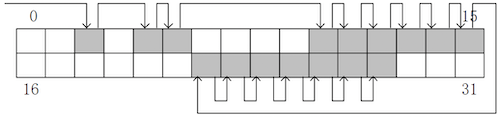
# 空闲块链表
将所有空闲的磁盘块链接成一个链表。文件系统只需保存链表的头指针。
# 文件系统的可靠性
文件系统的可靠性指其抵抗和预防各种物理及人为破坏的能力。数据丢失的代价远高于硬件损坏,因此可靠性至关重要。
# 数据备份与恢复
文件备份主要用于从意外灾难(如磁盘损坏)或错误操作(如误删文件)中恢复数据。备份通常是将磁盘文件转储到磁带等离线介质上。
# 物理转储
从磁盘的第一个块开始,按顺序将所有磁盘块的内容完整地复制到磁带上。
- 优点:实现简单,速度快。
- 缺点:无法跳过未使用空间,无法恢复单个文件,难以实现增量备份。
# 逻辑转储
从指定的目录开始,递归地转储自上次备份以来发生更改的文件和目录。
- 优点:备份内容更紧凑,支持增量备份,可以灵活地恢复单个文件或目录。
- 缺点:实现相对复杂。
# 文件系统一致性
文件的修改操作(读-改-写)并非原子操作。如果在所有修改过的数据块被写回磁盘之前系统崩溃,文件系统就可能处于不一致状态(例如,一个块既在文件中被引用,又在空闲列表中)。
文件系统一致性检查工具(如 fsck 或 chkdsk)用于检测和修复这些问题。
# 块的一致性检查
通过扫描所有 i 节点和空闲空间管理结构,为每个磁盘块建立两个计数器:一个记录它在文件中被引用的次数,另一个记录它在空闲列表中出现的次数。
- 块丢失:两个计数器都为 0。
- 解决方法:将该块添加到空闲列表中。
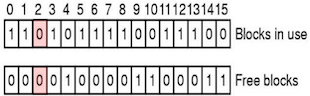
- 解决方法:将该块添加到空闲列表中。
- 空闲表中有重复块:在空闲列表中的计数大于 1。
- 解决方法:重建空闲列表。
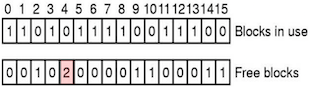
- 解决方法:重建空闲列表。
- 重复数据块:在文件中被引用的计数大于 1。
- 解决方法:分配一个新块,复制数据,并将其分配给其中一个文件,同时报告错误。
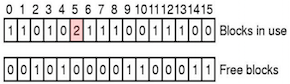
- 解决方法:分配一个新块,复制数据,并将其分配给其中一个文件,同时报告错误。
# 文件的一致性检查
通过扫描整个目录树,为每个文件(i 节点)建立一个引用计数,记录它在目录中出现的次数。然后将这个计数值与 i 节点中存储的链接计数值进行比较。
- i 节点的链接数 > 目录项数:
- 问题:可能存在文件数据块已分配,但没有任何目录指向它(“丢失的文件”)。
- 解决方法:将 i 节点中的链接数修正为正确的计数值(若为 0 则释放该文件)。
- i 节点的链接数 < 目录项数:
- 问题:可能多个目录项指向同一个 i 节点,但 i 节点中的链接数未能正确反映此情况,这可能导致文件被过早删除。
- 解决方法:将 i 节点中的链接数修正为正确的计数值。