# 预训练与微调
预训练(Pre-training) 为模型提供一个良好的初始参数估计。在这一阶段,模型通过海量数据学习通用的语言知识和模式。
微调(Fine-tuning) 则是在预训练的基础上,使用特定任务的数据集对模型进行进一步训练。若预训练效果良好,微调能更快地收敛到泛化能力强的局部最优解。
# 大语言模型(LLM)的代表性架构
BERT(Bidirectional Encoder Representations from Transformers)
- BERT 采用双向 Transformer 编码器。
- 核心训练任务是 Masked Language Model (Masked LM):用特殊标记
[MASK]替换输入中的部分词汇,然后预测这些被遮蔽的词,模型的损失只计算在这些被遮蔽词上。
GPT(Generative Pretrained Transformer)
- GPT 采用 Transformer 解码器,擅长生成任务。
- InstructGPT(指令微调技术):通过为每个 NLP 任务设计不同的提示模板,并用相应的指令和数据对模型进行微调。这使得模型在面对从未见过的新任务指令时,也能展现出零样本(Zero-shot) 任务解决能力,这体现了模型的泛化能力。
- RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习):
- 有监督微调:使用人工标注的高质量对话数据对模型进行微调。
- 奖励模型:训练一个模型来预测人类对模型输出的偏好分数。
- 策略优化:使用强化学习算法,根据奖励模型的分数来优化语言模型,使其产生更受人类偏好的回答。
- RLHF 的 Prompt(提示)通常来源于真实的用户请求。
# 语言模型的核心现象与能力
缩放法则(Scaling Laws)
- 模型的效果会随着计算量、数据集大小和参数数量的指数级增长而呈现线性提升。
涌现能力(Emergent Abilities)
- 当模型规模达到某个临界点时,模型的能力会突然大幅提升,而不是平稳增长。这种能力的出现与模型的具体结构关系不大,更多取决于其规模。
# 提示工程(Prompt Engineering)
提示工程是一种通过设计和优化输入文本(Prompt)来引导大语言模型产生所需输出的技术。
- 零样本提示(Zero-shot Prompting):直接将任务描述输入模型,不提供任何示例。
- 指令提示(Instruction Prompting):通过提供明确的指令或步骤来指导模型执行特定任务。
- 少样本提示(Few-shot Prompting):也称为上下文学习(In-Context Learning, ICL)。在提示中提供几个任务示例作为范本,然后让模型解决新问题。
- 这与微调(Fine-tuning) 截然不同,后者需要通过大量数据反复更新模型权重来实现训练。
- 也不同于指令微调,后者旨在让模型掌握在未见过的任务上泛化的能力。
- 思维链(Chain of Thought, CoT):
- 通过在提示中加入“Let's think step by step”(让我们一步步思考)等短语,引导模型输出具体的推理过程。
- 也可以将生成的推理步骤与最终问题拼接后重新提问。
- 该技术可用于零样本或少样本场景,但在模型规模足够大时才能展现出显著效果。
- 对推理任务效果明显,但对其他任务效果不一。
- 自洽性(Self-Consistency):
- 作为 CoT 的补充技术,通过多次生成不同的推理链条,然后选择多数派答案作为最终结果。
- 最少到最多提示(Least-to-most Prompting, LtM):
- 首先将一个复杂问题分解为多个子问题,然后逐一解决这些子问题。
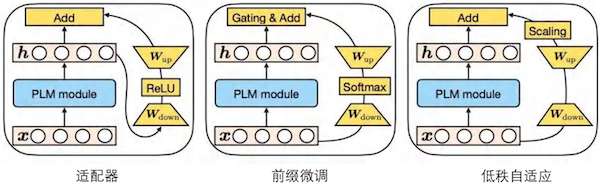
# 轻量化微调技术
这些技术旨在减少微调所需的计算和存储资源,同时保持预训练模型的强大能力。
-
LoRA(Low-Rank Adaptation,低秩自适应)
- 选择预训练模型中的特定权重矩阵(例如某层注意力机制的 )。
- 将其分解为两个低秩矩阵的乘积,只对这两个低秩矩阵进行微调。
- 显著减少了需要训练的参数量。
-
Adapter(适配器)
- 在预训练模型的每一层(或某些层)中添加一个小的 Adapter 模块。
- 微调时,冻结预训练模型的主体,仅训练这些 Adapter 模块来学习特定任务知识。
- Adapter 模块通常由一个降维层和一个升维层组成,形成一个“压缩-复原”的结构。
-
Prefix-Tuning(前缀微调)
- 在模型的输入前添加一个可训练的、特定于任务的连续向量序列,即“前缀”。
- 这个前缀完全由自由参数构成,与提示工程中的自然语言提示不同。
- 只需要训练这个非常小的、特定于任务的前缀,就能实现对模型的微调。