# Seq2Seq 概述
# 什么是 Seq2Seq?
Seq2Seq(Sequence-to-Sequence) 是一种神经网络架构,用于将一个序列转换为另一个序列,常用于神经网络机器翻译(NMT)。
Seq2Seq 模型是条件语言模型(Conditional Language Model) 的应用。在翻译任务中,解码器在预测下一个单词时,其预测过程是基于源句子 的条件进行的。其概率计算公式为:
# RNN NMT:编-解码器结构
早期的 Seq2Seq 模型通常采用循环神经网络(RNN) 作为其核心组件,其核心是编-解码器(Encoder-Decoder) 结构:
- 编码器(Encoder)RNN:负责读取输入序列,并将整个序列的信息压缩成一个最终隐藏状态。
- 解码器(Decoder)RNN:使用编码器传来的最终隐藏状态作为其初始隐藏状态,然后逐字生成目标序列。
整个模型通过端到端的方式进行训练。在训练过程中,通常会使用 “教师强制(Teacher Forcing)” 技术,即在预测下一个单词时,模型会使用真实的前一个单词作为输入,而不是模型自身的预测结果。
# 解码策略
在生成目标序列时,有多种解码策略可供选择,以在效率和准确性之间取得平衡。
- 贪心解码(Greedy Decoding):在每一步都选择概率最高的单词作为输出。这种方法虽然简单快速,但无法保证得到全局最优解。
- 穷举搜索解码(Exhaustive Search Decoding):理论上可以找到概率最大的序列,但其复杂度为 ,其中 是词汇表大小, 是目标序列长度,计算量巨大,在实践中不可行。
- 束搜索解码(Beam Search Decoding):这是一种介于前两者之间的启发式方法。它在每一步保留 个最有可能的候选路径(称为“束”或“Beam”),并跟踪这些路径。
- 束大小(Beam Size):通常取值为 5 到 10。
- 优点:比穷举搜索高效得多,同时通常能获得比贪心解码更好的结果。
- 缺点:并不能保证找到全局最优解。
- 停止条件:达到预设的最大时间步 ,或至少 个假设路径已经生成了结束符(
</s>)。 - 完成阶段:从所有已结束的路径中,选择归一化分数最高的路径作为最终输出。
# 带注意力机制的 NMT(Attention NMT)
传统的 RNN NMT 在处理长序列时表现不佳,因为编码器最终的隐藏状态无法有效承载整个长句子的所有信息。注意力机制(Attention Mechanism) 的引入解决了这一问题,并提供了一定的可解释性。
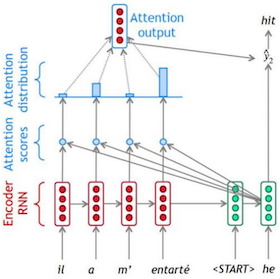
# 注意力机制工作流程
- 编码器(Encoder):对输入序列进行编码,生成一系列隐藏状态 。
- 解码器(Decoder):在每个时间步 ,解码器 RNN 基于上一个时间步的隐藏状态 和输出 ,生成当前隐藏状态 。
- 计算注意力得分:将当前解码器隐藏状态 与所有编码器隐藏状态 进行计算,得到注意力得分向量 。
- 生成注意力分布:对注意力得分 进行 softmax 操作,得到注意力权重分布 。
- 计算注意力输出:根据注意力分布对编码器隐藏状态进行加权求和,得到注意力输出向量 。
- 生成最终输出:将注意力输出 与当前解码器隐藏状态 拼接,然后通过分类层生成最终的输出词汇概率分布 。
# NMT 的优劣势
# 优势
相较于传统的统计机器翻译(SMT),神经网络机器翻译(NMT)具有显著优势:
- 流畅性:生成的译文更加流畅自然。
- 上下文利用:能够更好地利用上下文信息。
- 端到端系统:整个系统作为一个整体进行优化,无需单独优化子组件。
- 人力成本低:无需进行大量人工的特征工程,一套方法可以适用于多种语言对。
# 挑战与局限性
NMT 仍然面临一些挑战:
- OOV 问题:如何处理词汇表之外的未登录词(Out-of-Vocabulary, OOV)。
- 领域不匹配:训练数据与测试数据在领域上的差异会影响翻译质量。
- 长文本连贯性:在处理长篇幅文本时,难以保持上下文的全局连贯性。
- 资源稀缺:对于某些小语种,缺乏大规模的双语语料数据。
- 常识与文化:系统难以理解和翻译成语、俗语等需要常识和文化背景的表达。
- 偏见捕捉:模型可能从训练数据中习得并放大社会偏见。
- 黑箱问题:模型内部的工作机制复杂,有时会生成难以解释的奇怪翻译。