# 语义分割
# 目的
语义分割的目标是对图像中的每个像素进行分类,为每个像素分配一个类别标签。
# 评测指标
常用的评测指标是平均交并比 (mIoU) 和 F1 分数。
- 交并比 (IoU):计算预测区域与实际区域的重叠程度,公式为:
- F1 分数:是精确率和召回率的调和平均,公式为:
最终的评测结果通常是分别计算每个类别的 IoU 和 F1,然后取所有类别的平均值。
# 全卷积网络 (FCN)
全卷积网络 (FCN) 是一种输入和输出尺寸不变的卷积神经网络,是实现语义分割的基础。其核心思想是,将整个图像输入 FCN,得到与其尺寸一致的特征图,然后在此基础上进行逐像素分类。
由于直接处理高分辨率图像计算量巨大,FCN 通常会先进行下采样(如通过池化层)来减小特征图尺寸,再通过上采样恢复到原始图像尺寸进行逐像素预测。
# 上采样技术
上采样,也称为上池化 (Unpooling),是恢复特征图尺寸的关键步骤。常用的方法包括:
- 最近邻复制
- 补 0 填充:在最大池化时记住最大值的位置,上采样时将该值填充回原位,其余位置补 0。
- 双线性插值:通过周围像素的加权平均来计算新像素的值。公式如下:
- 可学习的上采样:转置卷积 (Transposed Convolution) 是其中一种常用方法。
# 转置卷积
转置卷积可以理解为卷积的逆过程,通过学习参数来实现上采样。
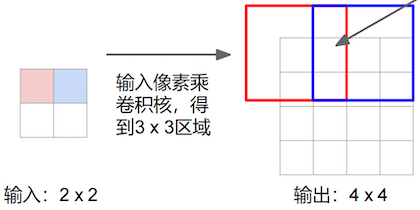
工作原理:
- 用卷积核在输入特征图上移动,每次对一个输入元素进行标量乘法,得到一个与卷积核大小相同的输出。
- 将所有输出按照步长(stride)进行组合。如果不同输出有重叠区域,则将重叠部分的值相加。
- 根据期望的输出尺寸和填充(padding),对最终输出进行裁剪或补 0。
矩阵表示示例(1D):
- 卷积:输入为 ,卷积核为 ,大小为 3,填充为 1,步长为 2。
- 转置卷积:输入为 ,卷积核为 。
# FCN 架构
FCN 通常以VGG等经典分类网络作为骨干,提取图像特征。
该架构的独特之处在于,它不仅对最终的预测结果进行上采样,还会将最终预测结果与网络中间层的预测结果进行融合。这种融合可以重复进行,得到不同精细程度的分割结果。
例如,将最后一层的预测上采样到原始图像尺寸,然后将该结果与一个更早的中间层(通常有更丰富的空间信息)的预测结果相加并再次上采样。这种多尺度融合有助于捕获更精细的细节,提高分割精度。
# 实例分割
# 目的
实例分割的目标是区分同一类别的不同物体。与语义分割不同,它不仅要识别每个像素的类别,还要将同一类别的不同个体实例(如多辆车)区分开。
# 实例分割的 FCN
# FCIS (Fully Convolutional Instance-aware Semantic Segmentation)
FCIS 是一种基于全卷积网络的实例分割模型。其主要步骤包括:
- 区域建议网络 (RPN):首先通过 RPN 生成感兴趣区域 (RoI)。
- Inside Score:对于每个 RoI,模型生成 张得分图,每张图对应 RoI 中的一个特定区域。然后将每张得分图对应区域合并,得到 RoI 的完整得分图。最后,应用逐像素的 Softmax,为每个像素在每个类别上分配一个概率,用于判断该像素是否属于该 RoI 前景。
- Outside Score:与 Inside Score 类似,但最后应用逐像素的 Max,为每个像素分配最可能的类别。通过取均值和投票(ave + vote),判断该 RoI 是否包含特定类别的物体。
组合情况:FCIS 可以处理三种情况:像素在该 RoI 中为前景且 RoI 包含该类别物体;像素在该 RoI 中为背景且 RoI 包含该类别物体;RoI 不包含该类别物体。
# Mask R-CNN
Mask R-CNN 是一个在 Faster R-CNN 基础上发展而来的实例分割模型。它在 Faster R-CNN 的基础上增加了两个额外的分支:
- Mask 预测网络:对每个 RoI 预测一个 的二值掩码 (binary mask),其中 是类别数。该网络判断 RoI 中的每个像素是前景还是背景。
- 关键点预测网络(可选):对每个 RoI 预测一个 的二值掩码,其中 是不同关键点的数量。该网络用于判断像素是否为关键点。在训练中,GT(Ground Truth)中的每个关键点都被标记为一个正像素,并用 Softmax Loss 进行训练。