# 评价指标
# IoU(Intersection over Union,交并比)
IoU 是衡量预测边界框(bounding box)与真实边界框重叠程度的指标。
# mAP(mean Average Precision,平均精度均值)
mAP 是衡量目标检测模型性能的综合指标,它结合了精度(Precision)和召回率(Recall)。
-
单个类别的 AP(Average Precision)计算
- 对一个类别,根据检测框的置信度从高到低进行排序。
- 依次取排名前 K 的检测框进行计算,其中 K 从 1 遍历到所有检测框。
- 每一步计算精确度(Precision)和召回率(Recall)。
- 精确度-召回率曲线(P-R Curve):以召回率为横轴,精确度为纵轴,绘制一条曲线。
- AP 是 P-R 曲线下的面积。
-
mAP 的计算
mAP 是对所有类别的 AP 求平均值。 -
特指当 IoU 阈值为 0.5 时计算得到的 AP 值。
# 经典目标检测模型
# DPM(Deformable Part-based Model,基于可变形部件的模型)
背景:Dalal & Triggs HOG 检测器
- 该检测器使用**HOG(梯度方向直方图)**特征,构建特征金字塔,并用线性分类器(如 SVM)在每个窗口上计算分数。
- 采用**非极大值抑制(NMS)**去除重叠度高的冗余边界框。
- 缺点:将物体建模为单个固定的模板,无法处理物体内部结构的可变性。
DPM 核心思想
DPM 引入了可变形部件的概念,认为一个物体由多个部件(如头部、躯干)组成,且这些部件的位置和尺度是可变的。
-
模型结构:
- 由一个**根模板(Root Filter)和多个部件模板(Part Filters)**组成。
- 模型参数通过训练得到,可直接使用已有的边界框数据进行训练。
-
检测流程:
- 构建多尺度图像金字塔。
- 根模板在图像金字塔的低分辨率层级上扫描,寻找潜在的整体轮廓。
- 部件模板在更高分辨率的层级上扫描,寻找与根模板关联的部件(如检测到大致的汽车轮廓后,部件模板会去寻找车轮、车窗等)。
- 计算候选对象的分数。
-
候选对象分数计算:
候选对象的分数是模板匹配分数与位移形变分数的总和。- :模板匹配分数。
- :第 个部件的过滤器权重向量( 为根过滤器)。
- :图像 在位置 处的子窗口特征向量。
- :位移形变分数。
- :第 个部件的变形参数,表示形变惩罚。
- :表示部件相对于其锚定点(根)的位移函数。
- 该项的具体形式为:
- :偏置项。
- :模板匹配分数。
-
最终得分:
在给定根位置 的前提下,通过最大化每个部件的位置,来得到最终得分。
# R-CNN 系列
1. CNN 检测单个窗口
- 方法:将单个窗口输入到 CNN,全连接层输出分类结果和边界框坐标。
- 损失函数:分类误差(Softmax)和边界框坐标误差(L2)的加权和。
2. 边界框回归
- 目的:通过 CNN 学习从预定义的候选框(或锚框)到真实目标框的偏移量,使训练过程更稳定。
- 回归公式:
- 和 分别是候选框的中心坐标和宽高。
- 和 分别是预测目标框的中心坐标和宽高。
- 是 CNN 学习到的偏移量。
- 优点:避免了宽高输出为负值,提供了平滑的尺度变化,并稳定了训练。
3. R-CNN
- 步骤:
- 使用**选择性搜索(Selective Search)**等方法生成大量可能包含物体的候选框。
- 将每个候选框中的图像内容缩放到固定大小,并输入到预训练的 CNN 中提取特征。
- 使用 SVM 对每个候选框进行分类,并使用边界框回归器修正边界框坐标。
- 缺点:计算速度慢,因为每个候选框都需要独立进行前向传播。
4. Fast R-CNN
-
核心思想:避免对每个候选框重复计算卷积特征。
-
步骤:
- 整张图像只进行一次 CNN 前向传播,得到一个共享的特征图。
- 利用选择性搜索生成的候选框,在特征图上找到对应的区域。
- 使用 RoI(Region of Interest)池化将每个区域的特征图裁剪并缩放到固定大小的特征向量。
- 将固定大小的特征向量输入到后续的全连接层,进行分类和边界框回归。
-
RoI 池化:
- 将每个 RoI 区域划分为 个子区域。
- 对每个子区域进行最大池化,得到一个固定大小为 的特征图。
-
RoI Align:
- RoI 池化存在量化误差,RoI Align 旨在解决此问题。
- 方法:不对齐的特征图进行量化,而是在每个 RoI 的子区域中均匀选取采样点,通过双线性插值计算这些点的特征值,然后进行池化。
5. Faster R-CNN
- 核心思想:用 CNN 取代选择性搜索,自动生成候选框。
- 主要组件:RPN(Region Proposal Network,区域候选网络)。
- RPN 流程:
- 在特征图的每个点上,定义一组锚框(Anchor Boxes),这些锚框具有不同的尺寸和长宽比。
- RPN 对每个锚框进行预测,判断其是否包含一个物体(前景或背景)。
- 对于被判断为前景的锚框,RPN 会同时预测从锚框到实际目标框的偏移量,以修正边界框坐标。
- 在实践中,通常对每个点使用 K 个锚框,并根据分数选择排名最高的若干个作为候选框。
- 整体损失函数:包含四部分
- RPN 的分类损失(前景/背景)。
- RPN 的边界框回归损失。
- 最终检测网络的分类损失。
- 最终检测网络的边界框回归损失。
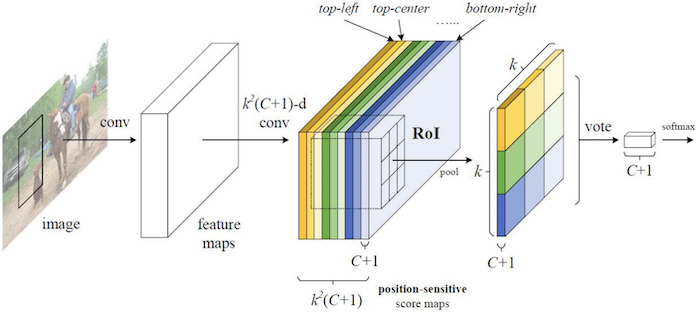
# R-FCN(Region-based Fully Convolutional Network)
-
核心思想:在不牺牲准确性的前提下,通过引入位置敏感的分数图,提高检测速度。
-
主要步骤:
- 使用预训练的 CNN 将图像转换为特征图。
- 在特征图上,使用一个具有 个通道的卷积层,生成位置敏感的得分图。其中, 是类别数, 是一个预定义的分辨率网格。
- 每个类别都有 个得分图,这些得分图分别对应于物体不同位置(如左上、右下)的特征。
- 对于每个 RoI,使用位置敏感的 RoI 池化。它从对应类别的 个得分图中,根据 RoI 内部的 区域,提取特征并进行池化。
- 将池化后的特征用于最终的分类和边界框回归。
-
图示:
-
优点:几乎所有的计算都在全卷积层中完成,大幅提高了效率。