# 降维:主成分分析(PCA)
# 算法概述
PCA 是一种无监督的降维算法,其核心思想是在保留数据最大方差的前提下,将高维数据映射到低维空间。
# 算法步骤
- 数据准备:假设每个样本有 k 个特征,共 n 个样本。每个样本 x 是一个 k×1 的列向量。
- 中心化:计算所有样本的均值 x,将每个样本减去均值以进行中心化处理,即 xcentered=x−x。中心化的目的是防止主成分方向偏向于数据中均值过大的特征。
- 归一化(可选):若不同特征的单位不统一,可以计算每个特征的方差并进行归一化。这确保了每个特征对主成分的贡献是平等的,防止主成分方向偏向于方差更大的方向。
- 构建矩阵:将所有中心化后的样本合并,形成一个 k×n 的矩阵 X。
- 计算协方差矩阵:计算协方差矩阵 M=XXT,其维度为 k×k。
- 特征值分解:对 M 进行特征值分解,得到 k 个特征值 λ1,λ2,…,λk 和对应的特征向量(主成分)e1,e2,…,ek。
- 投影:任取一个样本 x(i),其在特征空间中可表示为 x(i)=x+∑jgj(i)ej,其中第 j 个主成分的坐标为 gj(i)=ejT(x(i)−x)。
- 降维:为了实现降维,通常只保留那些特征值较大的前 m 个主成分,即对应的前 m 个特征向量。
# 算法性质与细节
- 方差与协方差:某个维度的主成分方差等于其对应的特征值,即 var(gk)=λk。不同维度主成分之间的协方差为零,即 cov(gk,gj)=0。
- 总方差:主成分方差之和等于原始特征方差之和,即 ∑kvar(gk)=∑kvar(xk)=∑kλk。
- 相关系数:原始特征 xj 与主成分 gi 的相关系数为 ρgi,xj=σjjeijλi,表示 xj 能被 gi 解释的部分。所有主成分对任意一个原始特征的解释程度平方和为 1,即 ∑iρgi,xj2=1。
- 坐标系:新坐标系的轴线沿着主成分(特征向量)方向。若样本经过中心化,新坐标系的原点位于样本均值处;否则,原点仍在 (0,0)。
- 计算复杂度:
- 计算所有特征值和特征向量的复杂度为 O(k3)。
- 计算前 m 个特征值和特征向量的复杂度为 O(mk2)。
- 优化方法:可使用随机化 PCA(快速寻找近似解)和增量 PCA(降低内存开销)来降低复杂度,或利用奇异值分解(SVD)近似。
# 图像特征:角点检测与常用滤波器
# Harris 角点检测
Harris 角点检测是一种用于识别图像中角点的经典算法。
# 算法步骤
- 区域划分与梯度计算:将图像划分为多个小区域,计算每个小区域内每个像素的 x 和 y 方向的梯度 Ix,Iy。梯度可通过差分或 Sobel 等卷积核来计算。
- 构建协方差矩阵:对每个小区域,构建一个 2×2 的协方差矩阵 M:
M=[∑Ix2∑IyIx∑IxIy∑Iy2]
- 特征值分析:计算矩阵 M 的特征值 λ1 和 λ2。
- 平滑点:λ1,λ2≈0。
- 边界:λ1≫λ2(垂直方向)或 λ1≪λ2(水平方向)。
- 角点:λ1,λ2 均较大且差异不明显。
- 角点响应值:通过角点响应值 R 定量判断,其中 R=det(M)−k⋅tr2(M)=λ1λ2−k(λ1+λ2)2。
- R≈0:平滑点。
- R<0:边界。
- R>0:角点。
- 非极大值抑制:对所有角点响应值进行非极大值抑制,以筛选出真正的角点。
# 算法特点
- 旋转不变性:算法对图像旋转不敏感。
- 尺度敏感性:算法对图像尺度变化敏感。
# 常用滤波器
# Gaussian 滤波器
- 作用:用于图像平滑和去噪。
- 表达式:
G(x,y)=2πσ21exp(−2σ2x2+y2)
- 卷积核:一个 3×3 的常见卷积核为 161121242121。卷积核的权重归一化是为了防止图像亮度发生变化。
# Sobel 滤波器
- 作用:用于边缘检测,基于一阶导数。
- 算子:∇f(x,y)=∂x∂f,∂y∂f。
- 卷积核:常用的 3×3 卷积核有:
Sx=−1−2−1000121,Sy=−101−202−101
# Laplacian 滤波器
# LoG (Laplace of Gaussian) 滤波器
- 作用:边缘检测,将拉普拉斯算子应用于高斯函数。
- 表达式:
LoG(x,y)=πσ41(1−2σ2x2+y2)exp(−2σ2x2+y2)
# DoG (Difference of Gaussian) 滤波器
- 作用:边缘检测,通过对图像应用不同标准差的高斯滤波器后进行差分得到。
- 特点:可以很好地近似 LoG 滤波器。
# 图像匹配
# 常用匹配方法
# 模板匹配
- 特点:对各种变换(旋转、尺度、亮度等)都非常敏感。
# 梯度匹配
# 颜色直方图 (Color Histogram)
- 原理:计算图像中不同颜色的像素数量并绘制直方图。
- 特点:对旋转和尺度变化不敏感,但没有考虑空间位置信息。
# 空间直方图 (Spatial Histogram)
- 原理:将图像分割成多个小区域(cell),并对每个 cell 分别计算颜色直方图。
- 特点:弥补了颜色直方图的不足,对部分空间变换不敏感。
# 基于特征的匹配方法
- 特点:对旋转、尺度和亮度变化具有不变性。
- 核心思想:
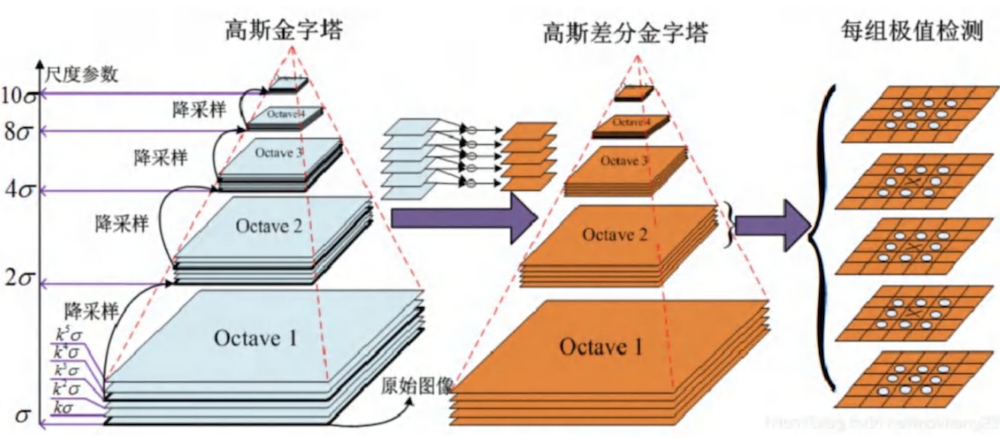
- 尺度空间构建:通过不同尺度的 Gaussian 滤波器构建图像金字塔(八度)。在同一八度内,对图像应用不同尺度的 Gaussian 卷积核;在相邻八度之间,通过降采样获得图像。
- 关键点检测:对相邻尺度的 Gaussian 图像进行差分得到 DoG 图像,然后对每个像素进行非极大值抑制,比较其在尺度空间(同一层 8 个,上下层各 9 个)共 26 个邻域点的值,找到局部极值点作为潜在关键点。
- 关键点精确定位:使用二次泰勒展开对 DoG 函数进行拟合,精确定位关键点的位置。
- 方向赋值:根据关键点邻域像素的梯度方向直方图,确定关键点的主方向,从而实现旋转不变性。
# SURF (Speeded Up Robust Features)
- 特点:比 SIFT 速度更快,对模糊和旋转具有鲁棒性,但对视角和光照变化敏感。
- 核心思想:
- Box Filter 近似:使用 Box Filter 来近似 DoG 滤波器。
- 积分图:利用积分图(Integral Image)技术快速计算 Box Filter 的卷积值,大幅提高计算速度。
# 学习型方法 (Learning based)
- 特点:
- 鲁棒性:对比例、遮挡、形变和旋转等变换更具鲁棒性。
- 性能:在特定任务上能超越传统方法。
- 缺点:训练耗时,需要大量数据集;泛化性可能较差,难以在不同场景中可靠泛化。
# 监督学习:线性回归与 SVM
# 线性回归
# 目标与损失函数
# 求解方法
- 闭式解:
- 将目标函数写成矩阵形式 L(θ)=21(Xθ−Y)T(Xθ−Y)。
- 通过对 θ 求梯度并令其为零,得到闭式解:θ^=(XTX)−1XTY。
- 梯度下降 (GD) 法:
- 迭代更新:θt+1=θt−α∇θL(θ),其中 α 是学习率。
- 学习率:学习率可以采用线性或指数衰减策略。
- 随机梯度下降 (SGD):每次迭代仅使用一个小批量(mini-batch)的数据来计算梯度。
- SGD 的优缺点:
- 优点:加快损失计算速度、降低内存消耗、具备更好的局部最优跳跃能力。
- 缺点:收敛速度变慢、震荡性强、不稳定。
- 避免局部最优:可使用动量法等高级优化器、在梯度中增加随机噪声或使用分批次的训练数据。
# 矩阵求导法则
- 基本规则:∇xf(x) 的第 ij 个元素为 ∂xi∂fj。
- 常用公式:
- ∇xAx=AT
- ∇xxTA=A
- ∇xxTAx=(A+AT)x
- ∇Atr(AB)=BT
# 支持向量机 (SVM)
# 目标与求解
- 目标:找到一个能够最大化两类样本到分界面距离(间隔)的分界面 wTx+b=0。
- 目标函数:通过约束优化,将问题转化为:
w,bmin21∥w∥22s.t.y(i)(wTx(i)+b)≥1
- 对偶问题:通过引入拉格朗日乘子,该问题可转化为对偶问题:
αmaxL(α)=i∑αi−21i,j∑y(i)y(j)αiαjx(i)Tx(j)s.t.i∑αiy(i)=0,αi≥0
# 优化与预测
- 优化方法:
- 二次规划 (QP):SVM 的对偶问题是一个二次规划问题。
- SMO 算法:通过每次只选择两个变量进行迭代优化,将复杂问题分解为简单的子问题。
- 预测:得到最优解 α∗ 后,可以计算 w∗=∑i∈SVαiy(i)x(i) 和 b∗,然后使用 y^test=sign(w∗Txtest+b∗) 进行预测。
# 非线性 SVM
- 核函数:通过将内积 x(i)Tx(j) 替换为核函数 K(x(i),x(j))=ϕ(x(i))Tϕ(x(j)),将数据从原始空间映射到更高维的特征空间,从而解决非线性问题。
- 常用核函数:多项式核、高斯(RBF)核和 Sigmoid 核。
# 深度学习基础
# 常用分类器
# 逻辑回归
- 激活函数:使用 Sigmoid 函数 σ(z)=1+exp(−z)1 将线性输出映射到 (0,1) 区间。
- 损失函数:通常使用交叉熵损失:
L(y,y^)=−ylog(y^)−(1−y)log(1−y^)
# 多分类
- Softmax 函数:将多个线性输出转换为概率分布,y^i=∑jexp(zj)exp(zi)。
- 交叉熵损失:用于多分类任务,当 y 为 one-hot 向量时,损失为 L=−∑jyjlog(y^j)。
# 聚类
- K-Means 算法:
- 分类:将每个样本分配到与其距离最近的中心点。
- 更新:将每个簇的中心点更新为该簇中所有样本的均值。
# 神经网络
# 激活函数
- Sigmoid:1/(1+e−x)。
- tanh:tanh(x)。
- ReLU:max(0,x),简单高效,但可能出现神经元死亡问题。
- Leaky ReLU:max(0.1x,x),解决了 ReLU 的神经元死亡问题。
- ELU:x (for x>0);α(ex−1) (for x<0)。
# 反向传播 (BP) 算法
- 计算方式:通常从网络输出端向输入端计算梯度,因为损失函数是标量,维度较低。
- 特点:可以有效避免重复计算,提高效率。
# 优化器
- 动量法:通过累积梯度来加速收敛,使用 βvt−1+(1−β)∇θJ(θ) 更新动量。
- RMSProp:自适应学习率,防止学习率过快或过慢。
- Adam:结合了动量法和 RMSProp 的优点,是目前最常用的优化器之一。
# 正则化
- 目的:缓解模型过拟合。
- L1/L2 正则:在损失函数中增加参数的范数惩罚项,L1 倾向于产生稀疏解。
- Dropout:在训练时随机使部分神经元失活,迫使网络学习冗余表示,防止特征的共适应性。
# 批标准化 (Batch Normalization)
- 原理:在网络每一层对 mini-batch 的输入进行归一化。
- 作用:加速训练、允许使用更大的学习率、减少对初始化的敏感性。
- 可学习参数:引入可学习的 γ 和 β 参数,以恢复模型的表达能力。
# 参数初始化
- 重要性:不能将所有参数初始化为零或相同的值,否则所有神经元将学习相同的特征。
- Xavier 初始化:适用于 Sigmoid 和 tanh 激活函数,其方差为 nin+nout2。
# 超参数调优
- 常见超参数:批次大小、学习率、动量、初始化方法、正则化参数、网络架构等。
- 调优策略:通常采用从粗粒度到细粒度的搜索策略,如网格搜索或随机搜索,并且可以通过在小数据集上观察模型是否过拟合来快速判断超参数的有效性。