# 模型构建
# Box-Jenkins 方法
Box-Jenkins 方法是构建 ARIMA 模型的经典流程,其基本步骤包括:
- 确定模型(Identification): 通过分析时间序列的性质,初步确定模型的类型和阶数。
- 估计参数(Estimation): 利用样本数据估计模型的具体参数。
- 模型诊断(Diagnostic Checking): 检验模型是否恰当,若不通过则返回第一步重新构建。
# ARIMA 模型构建步骤
以下是使用 Box-Jenkins 方法构建 ARIMA 模型的详细步骤:
-
数据预处理与平稳性检验
- 首先绘制时间序列图,直观了解数据的趋势和季节性。
- 对非平稳时间序列进行变换,如对数变换或差分,直到数据平稳。
- 计算并分析样本自相关函数(ACF)和偏自相关函数(PACF),确定差分次数 。如果时间序列存在单位根,需要持续差分直到其平稳。
-
模型定阶
- 通过分析 ACF、PACF 或 EACF(拓展自相关函数)等相关性图来初步确定模型的阶数 和 。
- 也可以利用信息准则,如 AIC、BIC 或 HQ 等,来选择最优的模型阶数。
- 相关性方法定阶
- MA(q) 模型: ACF 图在滞后 处截断(即 )。
- AR(p) 模型: PACF 图在滞后 处截断(即 )。
- ARMA(p,q) 模型: 采用 EACF 图,选择左上角且在其右下方向形成三角形的“圈”所对应的位置,该顶点即为 。
- 示例图:
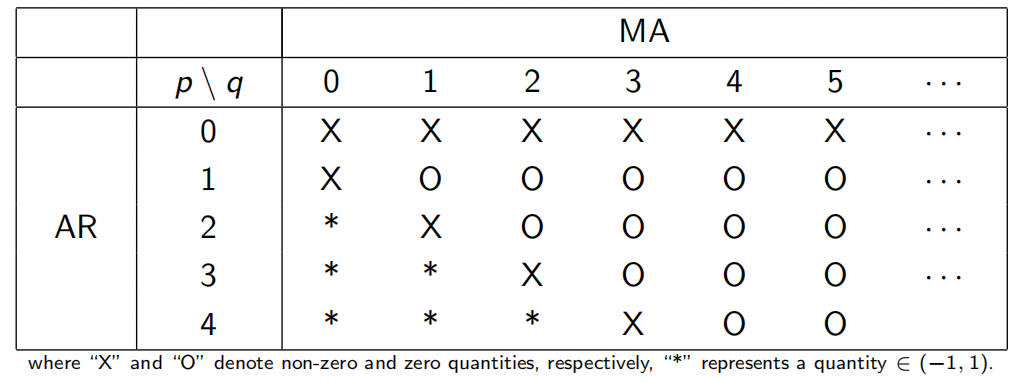
- 示例图:
-
参数估计
- 用数据估计已确定的 模型的参数。常用的估计方法包括:
- AR 模型: 最小二乘估计(LSE)、无条件 LSE、Yule-Walker 估计、条件最大似然估计(MLE)、MLE。
- ARMA 模型 / MA 模型: 条件 LSE、无条件 LSE、条件 MLE、MLE、最小绝对偏差估计(LADE)。
- 用数据估计已确定的 模型的参数。常用的估计方法包括:
-
模型诊断
- 对拟合好的模型进行诊断,以确认其能恰当地描述数据。如果诊断不通过,需要重新回到模型定阶步骤。
- 常用的诊断方法包括:
- 残差自相关性检验
- 检验残差的样本 ACF 是否接近于0。在原假设(残差无自相关)下, 近似服从 分布。
- Ljung-Box(LB)检验:检验前 个残差 ACF 的联合显著性。
在原假设下,LB 统计量近似服从 分布。
- 拉格朗日乘子(LM)原则。
- 残差同方差性检验
- 可通过异方差一致性 统计量进行检验。
- McLeod-Li(McL)检验:用于检验残差平方的自相关性。
在原假设下,McL 统计量近似服从 分布。
- 残差正态性检验
- 计算残差的偏度 和峰度 。
在正态性原假设下,,。
- Jarque-Bera(JB)检验:对正态性的联合检验。
在原假设下,JB 统计量近似服从 分布。
- 计算残差的偏度 和峰度 。
- 残差自相关性检验
# 模型选择信息准则
信息准则旨在平衡模型的拟合优度和复杂性,选择最优的模型。通用形式为:
- 赤池信息准则(AIC)
- 贝叶斯信息准则(BIC)